
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Community Tip - Did you get an answer that solved your problem? Please mark it as an Accepted Solution so others with the same problem can find the answer easily. X
- Community
- Creo+ and Creo Parametric
- System Administration, Installation, and Licensing topics
- Re: Mechanica: limiting (critical) hardware
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Mechanica: limiting (critical) hardware
Dec 22, 2010
11:51 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Dec 22, 2010
11:51 AM
Mechanica: limiting (critical) hardware
I'm wondering what the bottleneck is when running Mechanica analysis, hardware-wise.
We're currently running a large analysis on a 6 GB, quad-core machine. All the temporary files and results are going to the local hard disk, so there shouldn't be any significant network access (and the Task Manager graphs shows none).
Although Mechanica has recognised four cores (and occasionally uses them, getting more than 25% CPU usage), most of the time it's only at 5-10% CPU.
What's it waiting for? What hardware would increase the speed for these analyses? Do we need a fast RAID hard disk set-up, or faster memory, or more memory, or what?
This thread is inactive and closed by the PTC Community Management Team. If you would like to provide a reply and re-open this thread, please notify the moderator and reference the thread. You may also use "Start a topic" button to ask a new question. Please be sure to include what version of the PTC product you are using so another community member knowledgeable about your version may be able to assist.
Solved! Go to Solution.
Labels:
- Labels:
-
General
1 ACCEPTED SOLUTION
Accepted Solutions
Mar 07, 2011
03:23 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Mar 07, 2011
03:23 PM
Hi All,
I've been reading this discussion and thought I'd try to clarify a few points.
Hyper-threading
First, concerning hyper-threading, Burt's graphs clearly show that there is no benefit to using hyper-threading. We found similar results through our own testing and therefore recommend that users do not use hyper-threading.
Parallel Processing
For very large models, the most time consuming part of a Mechanica analysis is solving the global stiffness matrix equations. For this part of the analysis, Mechanica uses, by default, all of the available CPU cores for multiprocessing, up to a limit of 64 cores. Today, there are a few other parts of the analysis where Mechanica uses multiple cores and we plan to expand multiprocessing to other parts of the analysis in the future.
RAM and solram
The biggest influences on performance are the amount of RAM in your machine and how that RAM is used by Mechanica.
The amount of memory that use used during an analysis depends on several factors, including the complexity of the model, the desired accuracy of the solution, and the type of analysis or design study you are running. You can see how much total memory an analysis takes by looking at the bottom of the Summary tab of the Run Status dialog. The line you're looking for looks like this:
Maximum Memory Usage (kilobytes): XXXX
If the maximum memory usage of Mechanica plus the memory used by the OS and the other applications exceeds the amount of RAM in your machine, then the operating system (OS) will swap data between RAM and the hard disk, which seriously degrades the performance of your applications. Thus, to achieve maximum performance, you want to make sure that the maximum memory usage is less than the amount of RAM in your machine,
For very large models, the thing that requires the most memory during an analysis is the global stiffness matrix. You can see how big the global stiffness matrix is by looking on the Checkpoints tab of the Run Status dialog box (also in the .pas file in the study directory). The line you're looking for is
Size of global matrix profile (mb):
Mechanica allows you to limit the amount of memory that the global stiffness matrix will consume by setting the Memory Allocation field in the Solver Settings area of the Run Settings dialog.
We often call this Memory Allocation setting "solram". With this setting, you allocate a fixed amount of memory in which to hold slices of the global stiffness matrix that the linear equation solver works with at any one time. If the global stiffness matrix is too big to fit in solram, then Mechanica will swap part of the matrix back and forth between disk and RAM using an specialized swapping algorithm that is more efficient than the general swapping algorithm used by the OS.
To explain these concepts in more detail, I describe three different scenarios of how Mechanica using memory during an analysis.
Scenario I
Mechanica runs most efficiently when the entire global stiffness matrix fits in solram and when the total memory used by Mechanica fits in RAM.
For example, suppose you have a machine with 4 GB of RAM and 4 GB of disk allocated to swap space. You run an analysis which needs 1 GB for the global stiffness matrix, K, and 2 GB for everything else, which I'll call DB. If you set solram to 1.5 GB, then, ignoring the RAM used by the operating system and other applications, the memory usage looks like this.
Available: RAM swap
|--------------------------------|--------------------------------|
Used by Mechanica
:
DB K
****************(########----) Ideal
solram
DB + solram < RAM good (no OS swapping)
K < solram good (no matrix equation swapping)
In the above, the memory used by DB is shown as ****, the memory used by K is shown as ###, and the memory allocated to solram is inside parentheses (###--). Because K is smaller than solram, there is some memory that is allocated to solram that is unused, shown as ----. This is an ideal situation because the K < solram and DB + solram < RAM and hence, no swapping will occur.
Scenario II
Then next most efficient scenario is when the entire amount memory used by Mechanica still fits in RAM, but the global stiffness matrix does not fit in solram.
Available: RAM swap
|--------------------------------|--------------------------------|
Used by Mechanica
:
DB K
****************(#########)## OK
solram
DB + solram < RAM good (no OS swapping)
K > solram not so good (matrix equations will be swapped)
In this case, the part of K which does not fit in solram, shown above as ###, will be swapped to disk with specialized, efficient Mechanica code.
In this scenario, the size of solram has some, but not a large, effect on the performance of the analysis. In general, the larger solram is, the faster the global stiffness matrix equations will be solved, as long as the total memory used fits in RAM.
Scenario III
The worst case scenario is when the total memory used by Mechanica does not fit in RAM. If the total memory allocated by Mechanica (and all of the other processes running on your machine) exceeds the total RAM of your machine, then the operating system will swap data.
Available: RAM swap
|--------------------------------|--------------------------------|
Used by Mechanica:
DB K
***********************(################----) Bad
solram
DB + solram > RAM bad (OS will swap data)
K < solram doesn't really matter
In this scenario, the analysis will run slowly because the operating system will swap data. If this occurs, it's better to decrease solram so that memory that Mechanica uses remains in RAM, as shown below
Available: RAM swap
|--------------------------------|--------------------------------|
Used by Mechanica:
DB K
***********************(######)########## OK
solram
DB + solram < RAM good (no OS swapping)
K > solram not so good
(matrix equations will be swapped)
This is the same as scenario II above.
There are few other things to keep in mind.
- If you use a 32-bit Window OS, the maximum amount of memory that any one application can use is 3.2 GB.
- Solram is currently limited to a maximum of 8 GB. This maximum will be increased in a future release of Mechanica.
Here are some guidelines that you can follow to improve performance.
- Run on a machine with a 64-bit OS and lots of RAM.
- Exit other applications, so that Mechanica can use as much RAM as possible.
- Set solram low enough so that the total memory used by Mechanica is less than your total amount of RAM.
- If possible, set solram high enough so that the global stiffness matrix fits in solram (but don't violate guideline #3)
Disk Usage
The other major factor that influences performance is disk usage. During an analysis, Mechanica writes all of it's results to disk. Also, Mechanica temporarily stores on disk intermediate data that is required during the analysis. Although we haven't done detailed studies to determine their actual impact, the following guidelines should help improve performance.
- Make sure you are not using any drives that are mounted across the network.
- Use drives that have a generous amount of empty space on them.
- Occasionally defragment your disks so that data can be written and read in large contiguous blocks.
- Use fast hard drives.
- Use disk striping with a redundant array of independent disks (RAID) to increase IO performance.
- Use a RAM disk instead of a hard disk.
- Use a solid-state drive instead of a hard disk drive.
Sorry for the length of this note. It's more than I had originally intended to write, but I wanted to explain in detail how to get the maximum performance from your hardware for Mechanica. I would be curious to know if there are users out there who are already following these guidelines and what their real-world experiences are.
Tad Doxsee
PTC
47 REPLIES 47
Dec 23, 2010
04:30 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Dec 23, 2010
04:30 AM
Hi Jonathan,
Not really doing this recently but in the past one hassle was needing more memory than we had and then getting paging to HDD swapspace when we reached the limit. Probably not an issue with your setup but good to tick off to be sure. The next thing was setting the RAM that the solver is allowed to use. In older versions this defaulted to a really small amount of RAM (I guess to make sure it would not fail) so our rule of thumb for XP32 was to set solver RAM to half the available RAM e.g. 1GB for a 2GB machine (told you it was a while back). Early on we had the temporary files over the network problem but like you we sorted that out. Last but maybe relevant is the possibility for using solid state HDD for the temp files. Will be way quicker than any RAID setup with even high speed SCSI HDD and should not have to be that large for this type of work.
Hope some of this helps.
Regards,
Brent Drysdale
Dec 23, 2010
09:24 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Dec 23, 2010
09:24 AM
Well, for anyone who's interested I've found out some more today.
I discovered Windows perfmon.exe, and I've been watching disk and CPU usage while running the analysis.
I know that memory/hard disk swapping is an issue, as the run used all 6 GB of memory plus 15 GB of disk space.
Although Mechanica does use multiple cores, in practice it spends a long time meshing with just one core, and only uses more than two (>50% CPU) for brief moments. I've also read elsewhere than Mechanica only uses two cores, although that may be out of date.
Elapsed time for the run was 1h20m, with CPU time being 47m - not much, when you consider there was 5h20m available in total from the four cores!
The long spells of less than one core (<25% CPU) are mostly while disk writes or reads are happening (up to 70 GB/s on this machine, which sounds impressive to me although I don't know what drive(s) is(are) in it). There are also some periods of low CPU and much slower disk access, around 800 kB/s, which might suggest that both random-access and contiguous-transfer speeds are important at different times.
Therefore, I'd conclude that the requirements are:
1) As much memory as possible (not really a surprise).
2) The fastest single or dual core processor possible - there will be little advantage in a quad core (at the moment).
3) The fastest hard drive (SCSI, RAID, SSD or whatever) possible.
On the point about the memory allocation size (the value in Mechanica's Run->Settings dialogue box): when I did Mechanica training, the instructor told us that this was not a maximum, but a block size (the increment in which memory is allocated) and that increasing it (the default is 128 kB) would not help. Equally, I could believe that a larger block size might be more efficient on a computer with >4 GB - can anyone from PTC comment?
Feb 14, 2011
02:22 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Feb 14, 2011
02:22 AM
a couple of answers ....
If its using all the memory then this is your speed problem - once it starts paging to disk you're in for a long wait. Win7x64 and full RAM is the answer - just keep putting more RAM into the machine until the job runs with some memory headroom in Windows. If you cant get enough RAM into machine then you need to reduce the job size eg de-fillet model in non-critical areas.
Mechanica does use all cores allocated - we have a hex core i7 machine and it does use them HOWEVER only in a couple of phases - Equation Solve and Post Processing Calcs. All the rest is single threaded. Quad core is probably the best tradeoff. There needs to be a major rewrite to get more phases using more cores - maybe CREO.
Hyperthreading does NOTHING ! - it takes the same amount of time to run a job with H/T on (12 cores) as H/T off (6 cores) - theres just a heap of CPU thrash happening (2X the CPU time) go figure. Once again a rewrite is probably required to leaverage the H/T power of these new processors - maybe its not possible.
Memory allocation (SOLRAM) size doesnt seem to matter - you are actually better off leaving it low as it puts aside RAM which can cause a shortage elsewhere. Have a look in the *.pas files - it tells you what it should be set to - usually quite small.
More on this over at MCadCentral
http://www.mcadcentral.com/proe/forum/forum_posts.asp?TID=40699&PN=1&TPN=1
Frankly Mechanica's documentation is so out-of-date its laughable - they talk about 128M RAM. It really needs a major re-write - the results window needs to be properly integrated into ProE (FloEFD has superior integration). Unfortunately all our maintenance $'s were used to port it to CoCreate. Maybe CREO.
Can anyone comment from PTC where Mechanica is heading under CREO - are we going to get a proper re-write or just another port of the old girl ?
Shes still good but starting to show her age 
Feb 14, 2011
03:57 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Feb 14, 2011
03:57 AM
Interesting stuff about the .pas file and solram.
From the standard notes in .pas:
If the Mechanica Structure/Thermal
engine is the only memory-intensive application running on
your computer, performance will usually be best if you set
solram equal to half of your machine RAM. For example,
solram 60 is a good choice for a machine with 128 MB of RAM.
Setting solram to half machine
RAM is usually the best compromise...
[P]erformance may degrade significantly if you
set solram to 0.1 times machine RAM or less. A preferable
minimum is 0.25 times machine RAM.
As you say though, the actual suggested setting is tiny - 6 to 8 MB for some typical jobs, although the big run I was discussing above got the recommended value up to about 300 MB - which is still much lower than even 0.25× installed RAM! Sounds like it might be worth trying 512 or maybe 768 on large jobs but little more - unless, of course, the estimation routine isn't designed to work on machines with multiple GB...
Obviously, having enough memory to run the whole thing in RAM is desirable, but probably not realistic for bigger jobs - the MCADCentral thread also suggests that some fast disk space would be the next improvement.
Feb 14, 2011
04:39 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Feb 14, 2011
04:39 AM
The notes in the *.pas file are so ancient - I dont think the recommendations regarding 1/4 or 1/2 RAM make sense anymore. Try running with SOLRAM set above the recommended minimum from the *.pas file - try some different sizes (smaller & bigger) and see if it has any effect.
If you are running big jobs then just max an x64 machine out with RAM - its cheap enough to be economical compared with the time required to simplify models. Maybe paging with SATA3 RAID or SDD disk might work but Ive not seen any results that indicate that this is the case - Id be surprised as the bookkeeping would kill it.
Ill post some more data on hyperthreading in the next couple of days ...
Anyone out there from PTC who can shed some light on the SOLRAM setting in WF5 ?
woops - CREO/Elements 5 Pro/Mechanica something or other 
Feb 15, 2011
12:07 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Feb 15, 2011
12:07 AM
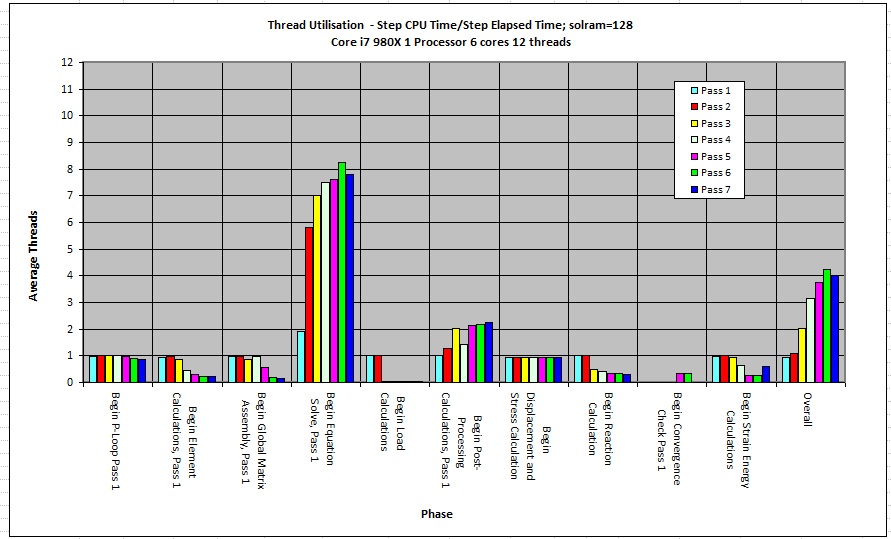
Heres a graph of how a hex Core i7 multithreads in Mechanica - mainly in Solver and some more in Post - and thats about it. Room for plenty of improvement there.
Feb 15, 2011
12:13 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Feb 15, 2011
12:13 AM
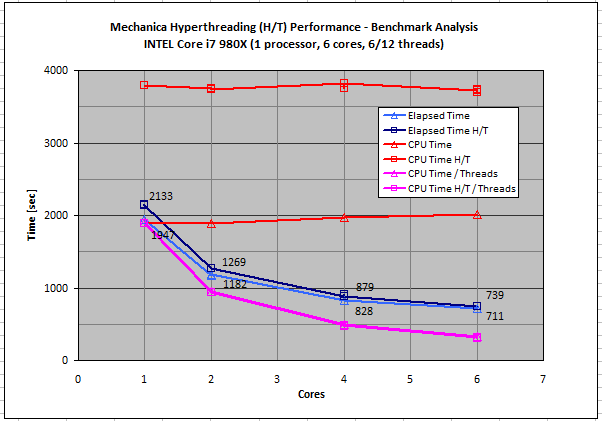
Another quite interesting graph - how Mechanica doesnt hyperthread at all !
The machine was set up to run, 1 core with and without H/T, 2 cores ... 6 cores with and without H/T.
Bluelines - the elapsed time is worse with H/T than without for all cores
Pinklines - best possible performance, actual performance becomes slightly less efficient with more cores.
Redlines - CPU time, double for H/T indicating computational thrash.
4 cores looks best compromise.
Mar 07, 2011
03:23 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Mar 07, 2011
03:23 PM
Hi All,
I've been reading this discussion and thought I'd try to clarify a few points.
Hyper-threading
First, concerning hyper-threading, Burt's graphs clearly show that there is no benefit to using hyper-threading. We found similar results through our own testing and therefore recommend that users do not use hyper-threading.
Parallel Processing
For very large models, the most time consuming part of a Mechanica analysis is solving the global stiffness matrix equations. For this part of the analysis, Mechanica uses, by default, all of the available CPU cores for multiprocessing, up to a limit of 64 cores. Today, there are a few other parts of the analysis where Mechanica uses multiple cores and we plan to expand multiprocessing to other parts of the analysis in the future.
RAM and solram
The biggest influences on performance are the amount of RAM in your machine and how that RAM is used by Mechanica.
The amount of memory that use used during an analysis depends on several factors, including the complexity of the model, the desired accuracy of the solution, and the type of analysis or design study you are running. You can see how much total memory an analysis takes by looking at the bottom of the Summary tab of the Run Status dialog. The line you're looking for looks like this:
Maximum Memory Usage (kilobytes): XXXX
If the maximum memory usage of Mechanica plus the memory used by the OS and the other applications exceeds the amount of RAM in your machine, then the operating system (OS) will swap data between RAM and the hard disk, which seriously degrades the performance of your applications. Thus, to achieve maximum performance, you want to make sure that the maximum memory usage is less than the amount of RAM in your machine,
For very large models, the thing that requires the most memory during an analysis is the global stiffness matrix. You can see how big the global stiffness matrix is by looking on the Checkpoints tab of the Run Status dialog box (also in the .pas file in the study directory). The line you're looking for is
Size of global matrix profile (mb):
Mechanica allows you to limit the amount of memory that the global stiffness matrix will consume by setting the Memory Allocation field in the Solver Settings area of the Run Settings dialog.
We often call this Memory Allocation setting "solram". With this setting, you allocate a fixed amount of memory in which to hold slices of the global stiffness matrix that the linear equation solver works with at any one time. If the global stiffness matrix is too big to fit in solram, then Mechanica will swap part of the matrix back and forth between disk and RAM using an specialized swapping algorithm that is more efficient than the general swapping algorithm used by the OS.
To explain these concepts in more detail, I describe three different scenarios of how Mechanica using memory during an analysis.
Scenario I
Mechanica runs most efficiently when the entire global stiffness matrix fits in solram and when the total memory used by Mechanica fits in RAM.
For example, suppose you have a machine with 4 GB of RAM and 4 GB of disk allocated to swap space. You run an analysis which needs 1 GB for the global stiffness matrix, K, and 2 GB for everything else, which I'll call DB. If you set solram to 1.5 GB, then, ignoring the RAM used by the operating system and other applications, the memory usage looks like this.
Available: RAM swap
|--------------------------------|--------------------------------|
Used by Mechanica
:
DB K
****************(########----) Ideal
solram
DB + solram < RAM good (no OS swapping)
K < solram good (no matrix equation swapping)
In the above, the memory used by DB is shown as ****, the memory used by K is shown as ###, and the memory allocated to solram is inside parentheses (###--). Because K is smaller than solram, there is some memory that is allocated to solram that is unused, shown as ----. This is an ideal situation because the K < solram and DB + solram < RAM and hence, no swapping will occur.
Scenario II
Then next most efficient scenario is when the entire amount memory used by Mechanica still fits in RAM, but the global stiffness matrix does not fit in solram.
Available: RAM swap
|--------------------------------|--------------------------------|
Used by Mechanica
:
DB K
****************(#########)## OK
solram
DB + solram < RAM good (no OS swapping)
K > solram not so good (matrix equations will be swapped)
In this case, the part of K which does not fit in solram, shown above as ###, will be swapped to disk with specialized, efficient Mechanica code.
In this scenario, the size of solram has some, but not a large, effect on the performance of the analysis. In general, the larger solram is, the faster the global stiffness matrix equations will be solved, as long as the total memory used fits in RAM.
Scenario III
The worst case scenario is when the total memory used by Mechanica does not fit in RAM. If the total memory allocated by Mechanica (and all of the other processes running on your machine) exceeds the total RAM of your machine, then the operating system will swap data.
Available: RAM swap
|--------------------------------|--------------------------------|
Used by Mechanica:
DB K
***********************(################----) Bad
solram
DB + solram > RAM bad (OS will swap data)
K < solram doesn't really matter
In this scenario, the analysis will run slowly because the operating system will swap data. If this occurs, it's better to decrease solram so that memory that Mechanica uses remains in RAM, as shown below
Available: RAM swap
|--------------------------------|--------------------------------|
Used by Mechanica:
DB K
***********************(######)########## OK
solram
DB + solram < RAM good (no OS swapping)
K > solram not so good
(matrix equations will be swapped)
This is the same as scenario II above.
There are few other things to keep in mind.
- If you use a 32-bit Window OS, the maximum amount of memory that any one application can use is 3.2 GB.
- Solram is currently limited to a maximum of 8 GB. This maximum will be increased in a future release of Mechanica.
Here are some guidelines that you can follow to improve performance.
- Run on a machine with a 64-bit OS and lots of RAM.
- Exit other applications, so that Mechanica can use as much RAM as possible.
- Set solram low enough so that the total memory used by Mechanica is less than your total amount of RAM.
- If possible, set solram high enough so that the global stiffness matrix fits in solram (but don't violate guideline #3)
Disk Usage
The other major factor that influences performance is disk usage. During an analysis, Mechanica writes all of it's results to disk. Also, Mechanica temporarily stores on disk intermediate data that is required during the analysis. Although we haven't done detailed studies to determine their actual impact, the following guidelines should help improve performance.
- Make sure you are not using any drives that are mounted across the network.
- Use drives that have a generous amount of empty space on them.
- Occasionally defragment your disks so that data can be written and read in large contiguous blocks.
- Use fast hard drives.
- Use disk striping with a redundant array of independent disks (RAID) to increase IO performance.
- Use a RAM disk instead of a hard disk.
- Use a solid-state drive instead of a hard disk drive.
Sorry for the length of this note. It's more than I had originally intended to write, but I wanted to explain in detail how to get the maximum performance from your hardware for Mechanica. I would be curious to know if there are users out there who are already following these guidelines and what their real-world experiences are.
Tad Doxsee
PTC
Mar 08, 2011
07:15 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Mar 08, 2011
07:15 AM
Tad,
We run big models.
Can you expand upon the hardwired solram=8192 limit?
is this removed in creo?
Thanks
Mar 08, 2011
03:29 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Mar 08, 2011
03:29 PM
Hi Charles,
I'm wondering, how big is big. For your big jobs, how big is the size of your global matrix profile (shown in the Checkpoints tab and the .pas file)? How much RAM is in the machine you run big jobs on?
For Creo 1.0, we plan to double the size of the maximum allowable solram from 8 GB to 16 GB.
Tad
Mar 09, 2011
08:04 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Mar 09, 2011
08:04 AM
Tad,
At the moment, 12 cores, 48Gb fast RAM and striped high speed SAS disks.
Just checked a study we ran Tuesday this week. Took just short of 9 hours, 75K elements with global matrix profile of 8.2Gb on pass 2, quite a few contacts (20 explicitly defined and 77 determined by the software) and minimal mesh refinements, often many fasteners (will fasteners still require 2 runs to get the preload right in creo? and is there sequentional load case application planned for creo?)
Of course, we only run big models when required and every opportunity is taken to reduce the size of the model. But a lot of geometry we deal with is not Pro/E native and therefore defeaturing can cost a lot of time. Even if pro/E native, castings with all their rounds and drafts can still present 'challenges'.
Often we deal with assemblies where there are complex load transfer paths that cannot be easily approximated as the movement of a structure changes load directions; in particular where there are contacts (is there finite friction contact in creo?). Therefore it becomes necessary to have levels of detail in the component being studied that is not normally reasonable at this assembly level.
We have carried out back to back studies and shown that even when putting what is a good approximation of a load system into a component that there can be significant differences; primarily because accounting for missing stiffness is difficult.
We have also manually 'submodelled' by using displacement measures. This is time consuming. (is there submodelling in creo?)
The compromise between prep time, degree of model abstraction and results accuracy is a constant battle and every now and again a bit more memory would be good...
ttfn
Mar 09, 2011
07:56 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Mar 09, 2011
07:56 PM
Hi Charles,
Yes, those are big models! Thanks for the information. It looks like the larger allowable solram in Creo 1.0 will help.
To answer some of your specific questions:
- "will fasteners still require 2 runs to get the preload right in creo?" Yes, in Creo 1.0, this is still a manual two-step process. We plan to improve this in a later release.
- "is there sequentional load case application planned for creo?" Yes. In Creo 1.0, if you are running a nonlinear analysis, you have the ability to specifiy the loading order (or "history") of every load in your model.
- "is there finite friction contact in creo?". Not in Creo 1.0, but this is an active area of promising research for us.
We understand the challenges you face when solving large, complex problems. Luckily machines keep getting more powerful, and we'll continue to try to improve the software to take advantage of the new hardware.
Tad
Mar 10, 2011
07:10 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Mar 10, 2011
07:10 AM
Tad,
Following on from the above discussion, I reviewed a recent project.
For one customer, the number of components did not change but the area of 'focus' for the study had to be moved around the model to remain within resonable run time limits (making full use of cheap night time electricity and labour).
50-70K elements was typical for a 'raw' mesh. It was when sufficient mesh refinements were added to get better mesh at the areas of focus could we have done with a bit more memory. (One model was 20Gb - though this was an exception rather than a rule).
Given that hardware cost to power is halving every year and that any purchasing department looking at 32bit platforms for an Engineer using a tool such as Mechanica should be fired, is the doubling of solram from 8 to 16 a software architectural limit or could it be opened right up in the future?
Any comments on the submodelling question?
Will the load "history" include bolt preloads? Bolt tightening order (possibly multi-stage tightening) is a common question.
Thanks
Mar 11, 2011
01:12 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Mar 11, 2011
01:12 PM
Hi Charles,
The current solram limitation is due to the fact that the global stiffness matrix equation solver was initially designed for 32 bit machines. This is a software issue that we can fix, and we plan to remove this limit in a future release.
Creo 1.0 will not have any sub-modeling capability.
When I mentioned contact in my last reply, I should have mentioned that you will be able to use contact interfaces in large deformation static analysis in Creo 1.0
Concerning your fastener question, we've found that many users who model fasteners with preloads are interested in knowing detailed information about the stresses near the fastener. These users like to model the fasteners with solid elements and use contact interfaces for maximum model fidelity. Therefore, in Creo 1.0, we are introducing a new type of preload that can be applied to any solid volume region. These preloads can be applied in any order, using the new load history functionality in Creo 1.0. This load history functionality is not yet available for the fastener connections.
Tad
Mar 15, 2011
06:18 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Mar 15, 2011
06:18 AM
Tad,
Your answers are a useful insight into future functionality. We all have to plan.
Load history, volume preloads, solram increase and contact large deflection are very welcome additionals to the list of functionality and I look forward to using it in anger. I would like to be reassured that it doesn't come hand in hand with the purchase of a 'guru' license to accompany the current basic and advanced.
My next questions would now about understanding the limitations of the implementation of the functionality ahead of time etc.
How can we users get deeper informtion about what will be in the next release without pestering you as I would rather you be working on the next tranche of enhancements?
Thanks
Mar 15, 2011
12:13 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Mar 15, 2011
12:13 PM
Hi Charles,
All of the functionality I described will be available if you have an existing advanced license. There is no new "guru" license needed. 
As we get closer to the relesae of Creo 1.0, all of the information about the new products will be available at www.ptc.com. Another great source of information about PTC product plans are the PlanetPTC Live events.
Tad
Apr 11, 2011
05:27 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Apr 11, 2011
05:27 PM
Tad,
We as well run some very large models similar in matrix size discussed in this chain. We have seen significant speed boosts as well with dual quad core processor and 12/24/32 Gb RAM configurations. The efficiency & speed of the displacement and stress calculation steps are our biggest bottleneck. On some of our bigger analysis jobs we are running 50-60 load cases which is dictated by the need to perform linear superposition with another tool. On some computers we may sit in this step for several hours. Since this step in the analysis is disk I/O intensive, I would assume that SSD or RAMDISK configurations may help us out. Do you have any studies that could show us ballpark time savings between typical HDD configurations and SSD / RAMDISK configurations?
Also, I think you could substantially improve the efficiency of this step in your process to allow for more configuration / controls on what output was requested. For example, if you allowed an option for calculating / writing stresses on the surface of solid elements, you will probably save a bunch of time and disk space. Other analysis programs also allow calculation output of specified stress calculations as well with 'groups' of results.
Apr 26, 2011
10:53 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Apr 26, 2011
10:53 PM
in the second part of Scenario III, shouldnt this read DB+solram < RAM
ie
Used by Mechanica:
DB K
***********************(######)########## OK
solram
DB + solram < RAM good (no OS swapping)
K > solram not so good
(matrix equations will be swapped)
Apr 27, 2011
11:24 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Apr 27, 2011
11:24 AM
Burt,
You're right. Thanks for pointing that out to me. I've fixed my previous post.
Tad
Apr 27, 2011
07:11 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Apr 27, 2011
07:11 PM
With regards the *.pas file theres the statement
Minimum recommended solram for direct solver: XXX
This appears to be less than "Size of global matrix profile (gb):"
How does this relate to your previous discussion?
It would be good if the NOTES in this file could be updated - not sure theyre optimal for the big RAM used today.
NOTES:
Solver RAM allocation can be done with a single parameter,
called solram. If the Mechanica Structure/Thermal
engine is the only memory-intensive application running on
your computer, performance will usually be best if you set
solram equal to half of your machine RAM. For example,
solram 60 is a good choice for a machine with 128 MB of RAM.
If you are running other memory-intensive applications on
your computer, decrease the solram allocation accordingly.
For example, set solram to 0.25 times machine RAM if you are
running two large applications at once. However, you often
can run two large jobs faster one after another than if you
try to run both jobs at once.
The purpose of solram is to reduce the amount of disk I/O.
If you set solram too high, performance will usually suffer,
even on machines with very large RAM, because there will not
be enough machine RAM for other important data. For
example, Mechanica allocates many large, non-solver
memory areas that will cause excessive swapping unless you
leave enough spare machine RAM. You must also leave enough
RAM for the operating system to do disk caching. Disk
caching improves filesystem performance by holding file data
in RAM for faster access. Setting solram to half machine
RAM is usually the best compromise between reducing the
amount of disk I/O, and leaving enough machine RAM for disk
caching and for other data.
If you set solram too low, performance will suffer because
Mechanica must transfer data between machine RAM and
disk files many more times than with a larger setting.
For example, performance may degrade significantly if you
set solram to 0.1 times machine RAM or less. A preferable
minimum is 0.25 times machine RAM.
The available swap space on your machine must be greater
than the maximum memory usage of your job. The available
disk space on your machine must be greater than the maximum
disk usage of your job. You can monitor the resource usage
of your job in the log (stt) file. Your job may fail if
your machine does not have enough available disk space or
swap space, or if the maximum memory usage of your job is
greater than the memory limits set for your operating
system.
Jan 04, 2012
11:12 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Jan 04, 2012
11:12 AM
Hi Tad,
I've just run a test with a RAM drive on my 24 GB quad-core machine.
A simple analysis, using about 52 MB on disk (according to the .rpt), dropped from 15 seconds to 10 seconds - a useful saving if you're doing a sensitivity study. Almost all that gain came from putting the temporary files on the RAM drive, rather than the results.
A much larger analysis (2.3 GB on disk, 2.5 GB of results) originally took around 45 minutes (I don't have exactly the same files to test with, but that's a reasonable estimate). Putting the temporary files on the RAM drive achieved a 38 minute run, but it was obvious that writing the results was painfully slow, with 12 separate files being updated together so lots of random write. I then ran it again with both temporary files and results on the RAM drive, and the elapsed time reduced to 13 minutes! Admittedly it took another minute or so to copy those results to the hard drive, but that's still a huge saving.
Summary: RAM drive well worth trying if you have plenty of spare RAM.
(I used imDisk, but that was just from a Google search - let me know if you have other options that work well.)
Jan 04, 2012
11:55 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Jan 04, 2012
11:55 AM
Hi Jonathan,
Going from 45 minutes to 13 minutes is indeed a great improvement in run time! Thanks for sharing your real-world experience. (I'm glad imDisk worked well for you. I don't have experience with other RAM disk drives.)
Tad Doxsee
PTC
May 17, 2012
05:58 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
May 17, 2012
05:58 PM
I did some benchmark testing to find the influence of SolRAM, RAM, and SSD vs. HDD on solution times.
Computer: i7 920 overclocked to 4.0 GHz, 12 GB RAM, Asus X58 mobo, WD Caviar Black 7200rpm 500GB HD, Patriot Pyro SE 64 GB SSD. (Both drives connected to a Marvell SATA III controller on the mobo, which is known to run slower than the full 6Gb/s rating.)
Program & model: Creo 1.0 student edition, linear elastic model, no contact or large deformation, both SPA and MPA used. Temp files were written to HDD or SSD, but output files were always written to HDD.
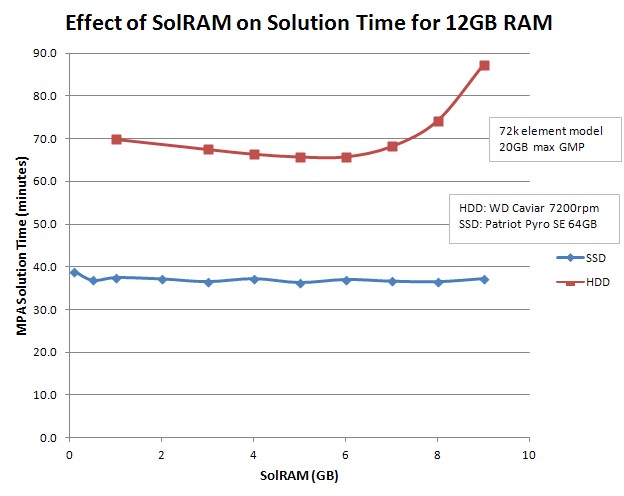
1. Optimum SolRAM for temp files written to HDD or SSD (MPA analysis):

- For temp files stored on HDD, setting SolRAM to 50% of total RAM is still optimum.
- For temp files stored on SSD, it doesn't really matter what SolRAM is set to, between roughly 5% and 75% of total RAM. Evidently the SSD is fast enough to not slow down the swapping algorithm one bit.
- The SSD gives a speedup of about 2 for this model and hardware config.
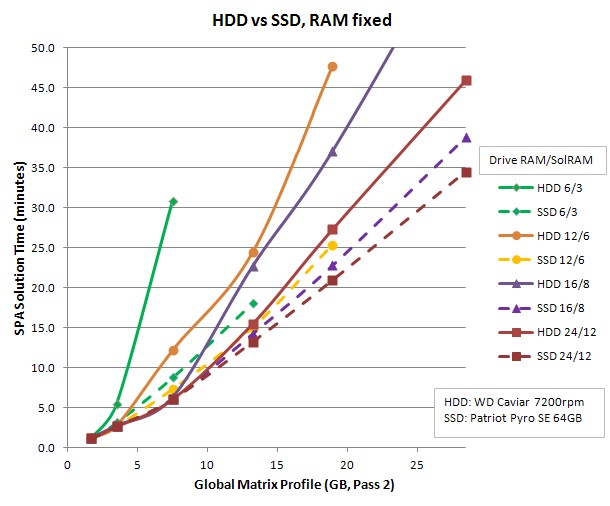
2. Next, the effect of both total RAM and SSD/HDD on solution times, for various model sizes (remeshed finer to give more elements and bigger Global Matrix Profiles). Each trace represents a certain hardware config of drive and RAM. SSD traces use dotted lines. All runs use SPA and SolRAM set to 50% of RAM.

- For a low RAM machine, if choosing between an SSD or more RAM, the SSD gives more speedup. As RAM increases, though, the SSD benefit is less. Max speedup is about 3.5 for the 6/3 case, falling to 1.3 for the 24/12 case. But, total RAM limits the max model size that can be solved.
- Most traces show a ~2x slope change at roughly 50% of total RAM. This likely relates to Tad's post on the GSM fitting in SolRAM.
3. Next, the same data is plotted but with each trace representing a fixed mesh size and global matrix profile, for both SSD and HDD.
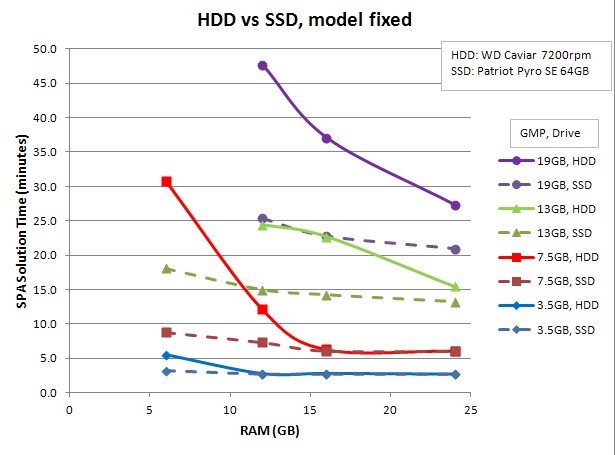
- The SSD gives a very wide range of speedups for the various models and hardware configs -- from 0 to 3.5.
- For GMP < 0.5*RAM there is no benefit for the SSD, The SSD speedup increases as GMP increases above 0.5*RAM.
- For the larger models, the speedup from a SSD is similar to doubling the RAM.
A few notes on SSDs:
- They have limited life for write-cycles. Most can write about 5000 times to each cell. At my rate of use, this 64 GB SSD will last about 2 years.
- It's usually best to setup a SSD with 10-15% of its space unpartitioned; this lets them write faster after all partitioned cells have been written to (better garage collection).
- An SSD's partitioned capacity has to be big enough to accept all temp file writes during a run. I'm finding the temp files total about the same size as the max GMP.
- Most SSDs use an internal controller made by Sandforce; these have fast reads but not the fastest writes for incompressible data (as written in FEA). Samsung's SSDs have their own internal controller, which are ~3x faster writing incompressible data. I'll be trying one of these in the future.
- An SSD should be hooked up to a SATA III 6 Gb/s port (gray on most motherboards) for fastest performance. SATA II will cut the SSD speed in half, but is fast enough for a HDD.
May 17, 2012
10:41 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
May 17, 2012
10:41 PM
interesting results - with these tests is Windoze on the HD or SSD?
May 21, 2012
02:42 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
May 21, 2012
02:42 PM
Win7 and Creo were both on the HDD. If on the SSD, I'd think that boot, program launch, and user input would be much faster on an SSD, but run times would probably be about the same. A while back, I put another FEA program (FEBio) on a RAM-disk and it didn't make any difference.
May 18, 2012
03:54 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
May 18, 2012
03:54 AM
Good information! Useful to see solram = 50% installed RAM confirmed as the optimum.
For the largest analyses, have you tried writing the results to SSD?
I've found significant improvements by writing results to a RAM drive - even counting the time to copy the results to a HDD afterwards - presumably due to the difference between random and sequential writes. Presumably SSD would give similar benefits.
In practice, most of our analyses now run sufficiently fast (< 5 min) that I don't consider it worth saving the results - I just print some results views to PDF, and if I want to look in more detail some months down the line I run the analysis again.
May 21, 2012
02:57 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
May 21, 2012
02:57 PM
Good to hear it's helpful!
I did try writing results to the SSD for a few of the moderate-sized models, and it helped some, but I didn't look at it systematically. That's interesting it can help significantly -- I'll check it with a larger model. Those are good points on just saving the relevant info to another file, and rerunning if needed -- often there are so many iterations and variables it's easier to be sure of them by rerunning.
May 25, 2012
07:16 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
May 25, 2012
07:16 PM
the links to the graphs have broken - is it possible to fix them?
Jun 01, 2012
02:03 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Jun 01, 2012
02:03 PM
I'm not sure why they went away, but here they are again:
Announcements
Top Tags

{kind=link}
{kind=link}