
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Community Tip - New to the community? Learn how to post a question and get help from PTC and industry experts! X
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Cluster Analysis - Agglomerative Nesting (AGNES)
Feb 18, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Feb 18, 2009
03:00 AM
Cluster Analysis - Agglomerative Nesting (AGNES)
AGGLOMERATIVE NESTING (AGNES) USING THE GROUP AVERAGE METHOD OF SOKAL AND MICHENER (1958)
As adapted from "L. Kaufman and P.J. Rousseeuw (1990), FINDING GROUPS IN DATA: AN INTRODUCTION TO CLUSTER ANALYSIS, New York: John Wiley." Chapter 5.
For those who believe all statistics are lies - rest assured there is no significance testing here - the decision for what is a seperate group and what is not is purely up to the researcher's own discretion.
Philip
___________________
Correct answers don't require correct spelling.
As adapted from "L. Kaufman and P.J. Rousseeuw (1990), FINDING GROUPS IN DATA: AN INTRODUCTION TO CLUSTER ANALYSIS, New York: John Wiley." Chapter 5.
For those who believe all statistics are lies - rest assured there is no significance testing here - the decision for what is a seperate group and what is not is purely up to the researcher's own discretion.
Philip
___________________
Correct answers don't require correct spelling.
Labels:
- Labels:
-
Statistics_Analysis
60 REPLIES 60
Feb 21, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Feb 21, 2009
03:00 AM
yech - patants are terrible things. They lock up useful things for no good reason. It is the greatest blocking factor in Information Technology. You can barely turn on your computer without breaking a patent.
For a while Puma Tech had a patent covering any type of data synchronisation based on a time or ID Token system (i.e. identity change number).
Ummm... try and make data sync without any type of time or ID tag. That was neither innovative nor really an "invention". It just made Puma Tech lots of money, Lawers lots of money and made software more expensive. What a massive loss of productivity!!!
My background is Applied Biology and Environmental Science (double major BSc) - so I did statistics (a lot of statistics), but never dealved into clustering, PCA/Factor analysis. I've more recently completed an MBA - but that was devoid of statistics.
I've done two honours (year of research), for both the BSc and MBA and both were statistics based. But again, neither was based of this area which is why I am teaching myself. Same as Baysian statistics - I've dabbled enough to know I don't know enough so I'm about to order some books on that.
So I'm not speaking from a position of authority on these areas. Please don't hold back telling me when I'm wrong because I don't know better but want to know. I have already picked up many pieces from this thread already. Thank you for the info so far.
R - is that a free software? Do you have some links for it? I have seen some books on it but I've never heard about it. I didn't know it was a programming language until your post just now.
Philip
___________________
Correct answers don't require correct spelling.
For a while Puma Tech had a patent covering any type of data synchronisation based on a time or ID Token system (i.e. identity change number).
Ummm... try and make data sync without any type of time or ID tag. That was neither innovative nor really an "invention". It just made Puma Tech lots of money, Lawers lots of money and made software more expensive. What a massive loss of productivity!!!
My background is Applied Biology and Environmental Science (double major BSc) - so I did statistics (a lot of statistics), but never dealved into clustering, PCA/Factor analysis. I've more recently completed an MBA - but that was devoid of statistics.
I've done two honours (year of research), for both the BSc and MBA and both were statistics based. But again, neither was based of this area which is why I am teaching myself. Same as Baysian statistics - I've dabbled enough to know I don't know enough so I'm about to order some books on that.
So I'm not speaking from a position of authority on these areas. Please don't hold back telling me when I'm wrong because I don't know better but want to know. I have already picked up many pieces from this thread already. Thank you for the info so far.
R - is that a free software? Do you have some links for it? I have seen some books on it but I've never heard about it. I didn't know it was a programming language until your post just now.
Philip
___________________
Correct answers don't require correct spelling.
Feb 21, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Feb 21, 2009
03:00 AM
I think I found the flaw in the AC.
Based on the link you sent I see that the "relative" distance is incorrect (scalling by the longest distance). The actual distance is what should be used.
Please review attachment and see if it is more accuratte.
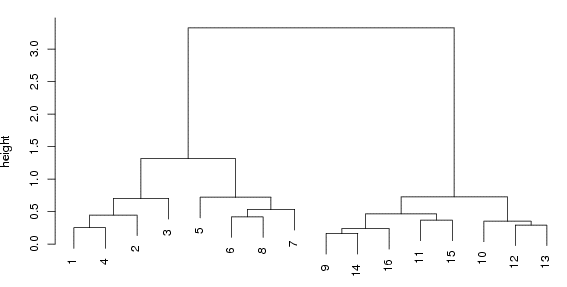
By the way - I LOVE the line combinations - dendogram. I've seen this in my books. It is effective, clear and I had no idea how to produce it.
Philip
___________________
Correct answers don't require correct spelling.
Based on the link you sent I see that the "relative" distance is incorrect (scalling by the longest distance). The actual distance is what should be used.
Please review attachment and see if it is more accuratte.
By the way - I LOVE the line combinations - dendogram. I've seen this in my books. It is effective, clear and I had no idea how to produce it.
Philip
___________________
Correct answers don't require correct spelling.
Feb 21, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Feb 21, 2009
03:00 AM
On 2/21/2009 6:59:13 AM, pleitch wrote:
>I think I found the flaw in
>the AC.
I think it's still wrong. If I feed the data into the web program I get AC=0.8877464975. That's high, which is what I would expect. I'm sure it's doing the same calculation, because this is the dendogram it produces:

The branches are not in the same order, but the groupings and (very importantly) the distances are identical. That's good, because it means that your program and the dendogram routine are correct.
When I read this:
"Let d(i) denote the dissimilarity of object i to the first cluster it is merged with, divided by the dissimilarity of the merger in the last step of the algorithm.
The agglomerative coefficient (AC) is defined as the average of all [ 1-d(i)]"
it says to me that you have to calculate AC as you go through each step of the clustering. That's why I didn't attempt to fix it. It needs to be calculated in your main program, and I didn't want to mess with that. I figured you could probably do it in less time that it would take me to figure out where to begin.
>By the way - I LOVE the line
>combinations - dendogram.
I wouldn't know what to do with a hierarchical clustering algorithm without it 🙂
Richard
>I think I found the flaw in
>the AC.
I think it's still wrong. If I feed the data into the web program I get AC=0.8877464975. That's high, which is what I would expect. I'm sure it's doing the same calculation, because this is the dendogram it produces:
The branches are not in the same order, but the groupings and (very importantly) the distances are identical. That's good, because it means that your program and the dendogram routine are correct.
When I read this:
"Let d(i) denote the dissimilarity of object i to the first cluster it is merged with, divided by the dissimilarity of the merger in the last step of the algorithm.
The agglomerative coefficient (AC) is defined as the average of all [ 1-d(i)]"
it says to me that you have to calculate AC as you go through each step of the clustering. That's why I didn't attempt to fix it. It needs to be calculated in your main program, and I didn't want to mess with that. I figured you could probably do it in less time that it would take me to figure out where to begin.
>By the way - I LOVE the line
>combinations - dendogram.
I wouldn't know what to do with a hierarchical clustering algorithm without it 🙂
Richard
Feb 21, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Feb 21, 2009
03:00 AM
On 2/21/2009 3:22:52 AM, pleitch wrote:
>yech - patants are terrible
>things.
Only when they are other peoples 🙂
>My background is Applied
>Biology and Environmental
>Science (double major BSc) -
>so I did statistics (a lot of
>statistics), but never dealved
>into clustering, PCA/Factor
>analysis. I've more recently
>completed an MBA - but that
>was devoid of statistics.
>
>I've done two honours (year of
>research), for both the BSc
>and MBA and both were
>statistics based. But again,
>neither was based of this area
>which is why I am teaching
>myself. Same as Baysian
>statistics - I've dabbled
>enough to know I don't know
>enough so I'm about to order
>some books on that.
Well, my only formal training in statistics was when I was force fed a dose of it during my physics degree. That did not cover anything to do with multivariate analysis, cluster analysis, etc. I have learned it from books, by listening to a lot of talks at conferences, and by getting a lot of advice from colleagues that know more about it than I do. In my field people usually avoid the term "statistics", and use the term "chemometrics" instead. I believe the term was coined because the statistics based algorithms are often applied to data and/or applied in a way that violates the statistical assumptions. So the results are not really statistical, but they work and are exceeding useful.
>R - is that a free software?
>Do you have some links for it?
>I have seen some books on it
>but I've never heard about it.
>I didn't know it was a
>programming language until
>your post just now.
I don't know much about it myself. I had someone recommend it to me about a year ago. He seemed to think it was the best thing since sliced bread (which, as it happens, I hate), but then he was a statistician. I think it's sort of a statistical Matlab. You can download it here:
http://www.r-project.org/
Richard
>yech - patants are terrible
>things.
Only when they are other peoples 🙂
>My background is Applied
>Biology and Environmental
>Science (double major BSc) -
>so I did statistics (a lot of
>statistics), but never dealved
>into clustering, PCA/Factor
>analysis. I've more recently
>completed an MBA - but that
>was devoid of statistics.
>
>I've done two honours (year of
>research), for both the BSc
>and MBA and both were
>statistics based. But again,
>neither was based of this area
>which is why I am teaching
>myself. Same as Baysian
>statistics - I've dabbled
>enough to know I don't know
>enough so I'm about to order
>some books on that.
Well, my only formal training in statistics was when I was force fed a dose of it during my physics degree. That did not cover anything to do with multivariate analysis, cluster analysis, etc. I have learned it from books, by listening to a lot of talks at conferences, and by getting a lot of advice from colleagues that know more about it than I do. In my field people usually avoid the term "statistics", and use the term "chemometrics" instead. I believe the term was coined because the statistics based algorithms are often applied to data and/or applied in a way that violates the statistical assumptions. So the results are not really statistical, but they work and are exceeding useful.
>R - is that a free software?
>Do you have some links for it?
>I have seen some books on it
>but I've never heard about it.
>I didn't know it was a
>programming language until
>your post just now.
I don't know much about it myself. I had someone recommend it to me about a year ago. He seemed to think it was the best thing since sliced bread (which, as it happens, I hate), but then he was a statistician. I think it's sort of a statistical Matlab. You can download it here:
http://www.r-project.org/
Richard
Feb 22, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Feb 22, 2009
03:00 AM
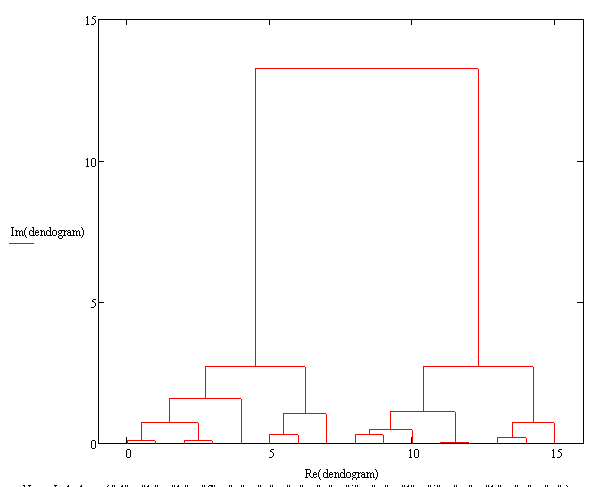
I've now been over this a number of times.
The book I use has the AC based on the banner.
The length of individual bands indicates the disimilarity. The banner's length is the distance divided by the largest distance (last join)
Therefore, this is a distance measured FROM 1. A distance value on the banner of 0.2 would indicate a distance of 0.8.
What I misuderstood was that not ALL lengths are measured. Only the lengths of the original items (e.g. "a", "b", "c") are counted, BUT are still measured in comparison to the last join of all groups. I was adding all the lengths. i means "item", NOT group.
The logic is that the last join is the largest seperation in groups. If all items are tightly clustered into seperate groups, where the groups are quite distant, then all the distance values will be low in comparison to the final group join.
So - how far the groups are away from eachother will "help", but only in the last join. Appart from that the AC is more of a measure of how quickly items are grouped, and how close to ach other items they are in comparison to the proximity of groups.
This value looks much better, but still isn't exact. I would put money on the calculations being slightly different, leading to a small difference in value to the R version.
Philip
___________________
Correct answers don't require correct spelling.
The book I use has the AC based on the banner.
The length of individual bands indicates the disimilarity. The banner's length is the distance divided by the largest distance (last join)
Therefore, this is a distance measured FROM 1. A distance value on the banner of 0.2 would indicate a distance of 0.8.
What I misuderstood was that not ALL lengths are measured. Only the lengths of the original items (e.g. "a", "b", "c") are counted, BUT are still measured in comparison to the last join of all groups. I was adding all the lengths. i means "item", NOT group.
The logic is that the last join is the largest seperation in groups. If all items are tightly clustered into seperate groups, where the groups are quite distant, then all the distance values will be low in comparison to the final group join.
So - how far the groups are away from eachother will "help", but only in the last join. Appart from that the AC is more of a measure of how quickly items are grouped, and how close to ach other items they are in comparison to the proximity of groups.
This value looks much better, but still isn't exact. I would put money on the calculations being slightly different, leading to a small difference in value to the R version.
Philip
___________________
Correct answers don't require correct spelling.
Feb 22, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Feb 22, 2009
03:00 AM
On 2/22/2009 4:50:24 AM, pleitch wrote:
>This value looks much better,
>but still isn't exact. I
>would put money on the
>calculations being slightly
>different, leading to a small
>difference in value to the R
>version.
You would have lost your money. It's a bug. Your indexing should start at 0, not 1 (Labels has no header row). Then the numbers match to within roundoff. I figured out how to get the distances from the web program too, and those also match to within roundoff (a rather more demanding comparison than just eyeballing dendograms!). So numerically, we are now golden.
I changed the functions slightly so that UPGMA takes the function name of the distance measure as a parameter. That makes it much easier to call it multiple times to compare the measures. I also added an autolabeling function, because I'm not into typing large vectors of arbitrary strings every time the data is changed.
Richard
>This value looks much better,
>but still isn't exact. I
>would put money on the
>calculations being slightly
>different, leading to a small
>difference in value to the R
>version.
You would have lost your money. It's a bug. Your indexing should start at 0, not 1 (Labels has no header row). Then the numbers match to within roundoff. I figured out how to get the distances from the web program too, and those also match to within roundoff (a rather more demanding comparison than just eyeballing dendograms!). So numerically, we are now golden.
I changed the functions slightly so that UPGMA takes the function name of the distance measure as a parameter. That makes it much easier to call it multiple times to compare the measures. I also added an autolabeling function, because I'm not into typing large vectors of arbitrary strings every time the data is changed.
Richard
Feb 22, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Feb 22, 2009
03:00 AM
Ahhh... fantastic.
Thanks for the colaboration with this.
Philip
___________________
Correct answers don't require correct spelling.
Thanks for the colaboration with this.
Philip
___________________
Correct answers don't require correct spelling.
Feb 22, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Feb 22, 2009
03:00 AM
On 2/22/2009 6:13:35 PM, pleitch wrote:
>Thanks for the colaboration
>with this.
This one definitely works both ways. I also wanted hierarchical cluster analysis in Mathcad, and you have done much more than half the work.
I think we need to add the calculation of AC to the UPGMA program too. It would make it much easier if it's called more than once with different parameters. I may do it tomorrow. I'll have UPGMA return a nested matrix with the current Groups matrix as one entry and AC as the other. That way it won't break the dendogram routine 🙂
Richard
>Thanks for the colaboration
>with this.
This one definitely works both ways. I also wanted hierarchical cluster analysis in Mathcad, and you have done much more than half the work.
I think we need to add the calculation of AC to the UPGMA program too. It would make it much easier if it's called more than once with different parameters. I may do it tomorrow. I'll have UPGMA return a nested matrix with the current Groups matrix as one entry and AC as the other. That way it won't break the dendogram routine 🙂
Richard
Feb 23, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Feb 23, 2009
03:00 AM
Although it would make sense to include it - I think I'll leave it seperate.
AC isn't frequently noted when calculating this measure. Out of three text books I have, only the book that ONLY deals with "finding groups in data" has it.
Also - will it make it quicker? I can't see that the AC calculation will actually take very long.
The AC can only be calculated at the end - because it measures the length of each item as (1 - Proportional Distance). The proportional distance is the distance of the item's join to the distance of the final join.
So you would need to have a check on each itteration to determine if one of the items is "singular", if so, add it to a running total. Then - at the end of the expression, divide all the "singular" distances by the number of items, then by the final distance...
Assume n is the number of Items
A minimum has been found:
? Is this a singular Item ?
If Yes
TotalDistance <- (TotalDistance + (CurrentDistance/n))
? Is this the final join ? //Note - not mutually exclusive to last if.
If Yes
AC <- (1-(TotalDistance/CurrentDistance))
On a final note.
I like the "auto-label" and "auto-scale". I also like the "Display Nested Matricies" - that isn't an option I knew about but went looking for it after I saw you use it. Also - adding comments with quotations marks is great. I would have added lots of comments if I had known about that.
Thanks again.
I'll probably be adding other distance measures to this shortly.... but first I'll give it a run with my company data.
Philip
___________________
Nobody can hear you scream in Euclidean space.
AC isn't frequently noted when calculating this measure. Out of three text books I have, only the book that ONLY deals with "finding groups in data" has it.
Also - will it make it quicker? I can't see that the AC calculation will actually take very long.
The AC can only be calculated at the end - because it measures the length of each item as (1 - Proportional Distance). The proportional distance is the distance of the item's join to the distance of the final join.
So you would need to have a check on each itteration to determine if one of the items is "singular", if so, add it to a running total. Then - at the end of the expression, divide all the "singular" distances by the number of items, then by the final distance...
Assume n is the number of Items
A minimum has been found:
? Is this a singular Item ?
If Yes
TotalDistance <- (TotalDistance + (CurrentDistance/n))
? Is this the final join ? //Note - not mutually exclusive to last if.
If Yes
AC <- (1-(TotalDistance/CurrentDistance))
On a final note.
I like the "auto-label" and "auto-scale". I also like the "Display Nested Matricies" - that isn't an option I knew about but went looking for it after I saw you use it. Also - adding comments with quotations marks is great. I would have added lots of comments if I had known about that.
Thanks again.
I'll probably be adding other distance measures to this shortly.... but first I'll give it a run with my company data.
Philip
___________________
Nobody can hear you scream in Euclidean space.
Feb 23, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Feb 23, 2009
03:00 AM
On 2/23/2009 12:51:42 AM, pleitch wrote:
>Although it would make sense
>to include it - I think I'll
>leave it seperate.
AC isn't
>frequently noted when
>calculating this measure. Out
>of three text books I have,
>only the book that ONLY deals
>with "finding groups in data"
>has it.
Also - will it make
>it quicker? I can't see that
>the AC calculation will
>actually take very long.
No, it would just make it easier to call it multiple times. I am a great believer in encapsulating everything in a function, rather than wring out the same code more than once.
The
>AC can only be calculated at
>the end - because it measures
>the length of each item as (1
>- Proportional Distance). The
>proportional distance is the
>distance of the item's join to
>the distance of the final
>join.
So you would need to
>have a check on each
>itteration to determine if one
>of the items is "singular", if
>so, add it to a running total.
>Then - at the end of the
>expression, divide all the
>"singular" distances by the
>number of items, then by the
>final distance...
Assume n
>is the number of Items
A
>minimum has been found:
? Is
>this a singular Item ?
If Yes
>TotalDistance <-
>(TotalDistance +
>(CurrentDistance/n))
? Is this
>the final join ? //Note - not
>mutually exclusive to last
>if.
If Yes
AC <-
>(1-(TotalDistance/CurrentDista
>nce))
You are making it sound much more difficult than it is. I was just going to tag it on to the end of the routine, right before you return "Results."
>I'll
>probably be adding other
>distance measures to this
>shortly....
In my experience what makes a much bigger difference to the clustering is the linkage: i.e. eUPGMA. What you have is the average linkage, but there are lots of others. single, complete, and centroid are common. I have had a lot of success with Ward's method in the past.
Richard
>Although it would make sense
>to include it - I think I'll
>leave it seperate.
AC isn't
>frequently noted when
>calculating this measure. Out
>of three text books I have,
>only the book that ONLY deals
>with "finding groups in data"
>has it.
Also - will it make
>it quicker? I can't see that
>the AC calculation will
>actually take very long.
No, it would just make it easier to call it multiple times. I am a great believer in encapsulating everything in a function, rather than wring out the same code more than once.
The
>AC can only be calculated at
>the end - because it measures
>the length of each item as (1
>- Proportional Distance). The
>proportional distance is the
>distance of the item's join to
>the distance of the final
>join.
So you would need to
>have a check on each
>itteration to determine if one
>of the items is "singular", if
>so, add it to a running total.
>Then - at the end of the
>expression, divide all the
>"singular" distances by the
>number of items, then by the
>final distance...
Assume n
>is the number of Items
A
>minimum has been found:
? Is
>this a singular Item ?
If Yes
>TotalDistance <-
>(TotalDistance +
>(CurrentDistance/n))
? Is this
>the final join ? //Note - not
>mutually exclusive to last
>if.
If Yes
AC <-
>(1-(TotalDistance/CurrentDista
>nce))
You are making it sound much more difficult than it is. I was just going to tag it on to the end of the routine, right before you return "Results."
>I'll
>probably be adding other
>distance measures to this
>shortly....
In my experience what makes a much bigger difference to the clustering is the linkage: i.e. eUPGMA. What you have is the average linkage, but there are lots of others. single, complete, and centroid are common. I have had a lot of success with Ward's method in the past.
Richard
Feb 23, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Feb 23, 2009
03:00 AM
RE Tag it on the end... Yeah - that will work... but it will be slower than what I suggested.
Probably won't notice much unless the are lots and lots of objects.
Ward's method - also known as ESS or Error Sum of Squares - is one of the next couple I am doing (litterally implementing now).
If you want to wait off - I'll have it done soon.
Philip
___________________
Nobody can hear you scream in Euclidean space.
Probably won't notice much unless the are lots and lots of objects.
Ward's method - also known as ESS or Error Sum of Squares - is one of the next couple I am doing (litterally implementing now).
If you want to wait off - I'll have it done soon.
Philip
___________________
Nobody can hear you scream in Euclidean space.
Feb 23, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Feb 23, 2009
03:00 AM
On 2/23/2009 6:43:24 PM, pleitch wrote:
>RE Tag it on the end... Yeah -
>that will work... but it will
>be slower than what I
>suggested.
>
>Probably won't notice much
>unless the are lots and lots
>of objects.
But no slower than it is now. Thinking about it though, maybe the right thing to to is just encapsulate AC in it's own function. Then if you don't need it, the execution time is zero 🙂
>Ward's method - also known as
>ESS or Error Sum of Squares -
>is one of the next couple I am
>doing (litterally implementing
>now).
I haven't heard it called that, but that's not surprising. If you want to check it's working correctly, that R-based web program also does Wards method.
>If you want to wait off - I'll
>have it done soon.
I am not one to unnecessarily duplicate work!
Richard
>RE Tag it on the end... Yeah -
>that will work... but it will
>be slower than what I
>suggested.
>
>Probably won't notice much
>unless the are lots and lots
>of objects.
But no slower than it is now. Thinking about it though, maybe the right thing to to is just encapsulate AC in it's own function. Then if you don't need it, the execution time is zero 🙂
>Ward's method - also known as
>ESS or Error Sum of Squares -
>is one of the next couple I am
>doing (litterally implementing
>now).
I haven't heard it called that, but that's not surprising. If you want to check it's working correctly, that R-based web program also does Wards method.
>If you want to wait off - I'll
>have it done soon.
I am not one to unnecessarily duplicate work!
Richard
Feb 24, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Feb 24, 2009
03:00 AM
Done - check my recent posts.
Just to be clear, it isn't called ESS/Error sum of squares. However, it is based on this. It finds the Euclidean distances between the objects of the cluster and it's centroid. So instead of determining distances to combine close objects, it is determining the next objects that would combine to create the next smallest group (i.e. the next tightest group of objects). That way the focus is on creating small groups - stepping out to larger groups as apposed to joining close objects together as possible.
At least... this is my understanding.
Philip
___________________
Nobody can hear you scream in Euclidean space.
Just to be clear, it isn't called ESS/Error sum of squares. However, it is based on this. It finds the Euclidean distances between the objects of the cluster and it's centroid. So instead of determining distances to combine close objects, it is determining the next objects that would combine to create the next smallest group (i.e. the next tightest group of objects). That way the focus is on creating small groups - stepping out to larger groups as apposed to joining close objects together as possible.
At least... this is my understanding.
Philip
___________________
Nobody can hear you scream in Euclidean space.
Feb 24, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Feb 24, 2009
03:00 AM
On 2/24/2009 1:09:40 AM, pleitch wrote:
>Done - check my recent posts.
>
>Just to be clear, it isn't
>called ESS/Error sum of
>squares. However, it is based
>on this. It finds the
>Euclidean distances between
>the objects of the cluster and
>it's centroid. So instead of
>determining distances to
>combine close objects, it is
>determining the next objects
>that would combine to create
>the next smallest group (i.e.
>the next tightest group of
>objects). That way the focus
>is on creating small groups -
>stepping out to larger groups
>as apposed to joining close
>objects together as possible.
>
>At least... this is my
>understanding.
Sounds about right. Here's another description:
"The previous algorithms merge the two groups which are most similar. Ward's Algorithm, however, tries to find as homogeneous groups as possible. This means that only two groups are merged which show the smallest growth in heterogeneity factor H. Instead of determining the spectral distance, the Ward�s Algorithm determines the growth of heterogeneity H."
Richard
>Done - check my recent posts.
>
>Just to be clear, it isn't
>called ESS/Error sum of
>squares. However, it is based
>on this. It finds the
>Euclidean distances between
>the objects of the cluster and
>it's centroid. So instead of
>determining distances to
>combine close objects, it is
>determining the next objects
>that would combine to create
>the next smallest group (i.e.
>the next tightest group of
>objects). That way the focus
>is on creating small groups -
>stepping out to larger groups
>as apposed to joining close
>objects together as possible.
>
>At least... this is my
>understanding.
Sounds about right. Here's another description:
"The previous algorithms merge the two groups which are most similar. Ward's Algorithm, however, tries to find as homogeneous groups as possible. This means that only two groups are merged which show the smallest growth in heterogeneity factor H. Instead of determining the spectral distance, the Ward�s Algorithm determines the growth of heterogeneity H."
Richard
Feb 23, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Feb 23, 2009
03:00 AM
>>
>> I
>>would put money on the
>>calculations being slightly
>>different, leading to a small
>>difference in value to the R
>>version.
>
>You would have lost your money. It's a
>bug.
>Richard
Just a quick comment - there's a reason I don't gamble!
Philip
___________________
Nobody can hear you scream in Euclidean space.
Feb 24, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Feb 24, 2009
03:00 AM
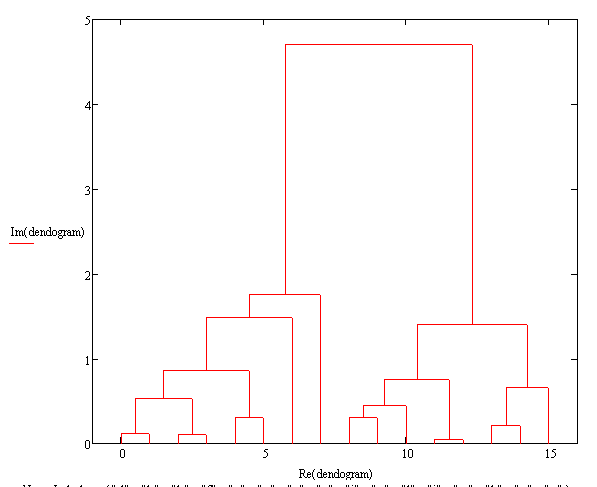
Attached with Ward's method.
Ward's method uses a completely different approach, so I had to re-program some areas.
What I am hoping to achieve is a worksheet that I can plug values in the top, then using a radio button or combo box, select the appropriate method AND distance calculation. So this is still a work in progress.
A warning on Ward:
It is extremely sensitive to outliers.
Ward's method makes dissimilarity blow up to infinity. "Indeed, in many real data sets we have noticed that the final level of Ward's clustering was much larger than the largest dissimilarity between any two objects." therefore "The dissimilarity of a single linkage will tend to 0: The more points you draw from two strictuly postive densities, the closer will be their nearest neighbors. For any two such densities, their limiting dissimilarity becomes 0."
What's all that mean? Just check oout the Histograms:
Philip
___________________
Nobody can hear you scream in Euclidean space.
Ward's method uses a completely different approach, so I had to re-program some areas.
What I am hoping to achieve is a worksheet that I can plug values in the top, then using a radio button or combo box, select the appropriate method AND distance calculation. So this is still a work in progress.
A warning on Ward:
It is extremely sensitive to outliers.
Ward's method makes dissimilarity blow up to infinity. "Indeed, in many real data sets we have noticed that the final level of Ward's clustering was much larger than the largest dissimilarity between any two objects." therefore "The dissimilarity of a single linkage will tend to 0: The more points you draw from two strictuly postive densities, the closer will be their nearest neighbors. For any two such densities, their limiting dissimilarity becomes 0."
What's all that mean? Just check oout the Histograms:
Philip
___________________
Nobody can hear you scream in Euclidean space.
Feb 24, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Feb 24, 2009
03:00 AM
Post post post.... sorry for all the posts in quick succession - but I forgot to say that I have bookmarked that R page and I have been using it as a cross-check.
Ward checks out (both values and AC).
Cheers,
Philip
___________________
Nobody can hear you scream in Euclidean space.
Ward checks out (both values and AC).
Cheers,
Philip
___________________
Nobody can hear you scream in Euclidean space.
Feb 24, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Feb 24, 2009
03:00 AM
On 2/24/2009 1:12:17 AM, pleitch wrote:
>Ward checks out (both values
>and AC).
Cool. Saves me doing it 🙂
Richard
>Ward checks out (both values
>and AC).
Cool. Saves me doing it 🙂
Richard
Feb 24, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Feb 24, 2009
03:00 AM
On 2/24/2009 12:55:14 AM, pleitch wrote:
>Attached with Ward's
>method.
>Ward's method uses a
>completely different approach,
>so I had to re-program some
>areas.
What's the point of the "Null" distance? You can't use it with the average linkage (at least, not meaningfully), and Ward's method doesn't use the distances so it doesn't matter what the distance metric is.
>What I am hoping to
>achieve is a worksheet that I
>can plug values in the top,
>then using a radio button or
>combo box, select the
>appropriate method AND
>distance calculation. So this
>is still a work in
>progress.
Yes, that would be my goal too. I can add a bunch of that stuff, but I have a long trip coming up in a couple of days (3-4 weeks in Asia) and I have a lot to do before I go so I'm not sure when I'll get to it.
Richard
>Attached with Ward's
>method.
>Ward's method uses a
>completely different approach,
>so I had to re-program some
>areas.
What's the point of the "Null" distance? You can't use it with the average linkage (at least, not meaningfully), and Ward's method doesn't use the distances so it doesn't matter what the distance metric is.
>What I am hoping to
>achieve is a worksheet that I
>can plug values in the top,
>then using a radio button or
>combo box, select the
>appropriate method AND
>distance calculation. So this
>is still a work in
>progress.
Yes, that would be my goal too. I can add a bunch of that stuff, but I have a long trip coming up in a couple of days (3-4 weeks in Asia) and I have a lot to do before I go so I'm not sure when I'll get to it.
Richard
Feb 25, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Feb 25, 2009
03:00 AM
>
>What's the point of the "Null" distance?
>You can't use it with the average
>linkage (at least, not meaningfully),
>and Ward's method doesn't use the
>distances so it doesn't matter what the
>distance metric is.
Ward doesn't need it - but the existing procedure still called it. So to avoid re-writing the procedure I supplied a distance method that didn't calculate anything.
So this was to ensure all the other functions would work in-place (without modification), even though some methds don't use them.
(I played with a couple of ideas - i think that's how I left it).
>>What I am hoping to
>>achieve is a worksheet that I
>>can plug values in the top,
>>then using a radio button or
>>combo box, select the
>>appropriate method AND
>>distance calculation. So this
>>is still a work in
>>progress.
>
>Yes, that would be my goal too. I can
>add a bunch of that stuff, but I have a
>long trip coming up in a couple of days
>(3-4 weeks in Asia) and I have a lot to
>do before I go so I'm not sure when I'll
>get to it.
You have already added quite a lot. Distance measures, dendograms and so on.
FYI - I'll be adding some other methods, including centroid, over the next few days. So
I'll also clean up some of the names. ED stands for Euclidean Distance matrix - but that isn't valid any more. I've really enjoyed this little project.
If you are traveling to Australia, let me know - our paths might cross.
Cheers,
Philip
___________________
Nobody can hear you scream in Euclidean space.
Feb 25, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Feb 25, 2009
03:00 AM
On 2/25/2009 7:35:21 AM, pleitch wrote:
>Ward doesn't need it - but the
>existing procedure still
>called it. So to avoid
>re-writing the procedure I
>supplied a distance method
>that didn't calculate
>anything.
But why not just ignore it? It doesn't matter what the distance method is. If you wanted some minor time saving, why not just set all the elements to 0?
>If you are traveling to
>Australia, let me know - our
>paths might cross.
No. I have to go to Bali first, then Beijing. It's all business, but I'll slot in some personal time in Bali (would be dumb not to!). I've been to Beijing so many times that's just another long business trip 😞
Richard
>Ward doesn't need it - but the
>existing procedure still
>called it. So to avoid
>re-writing the procedure I
>supplied a distance method
>that didn't calculate
>anything.
But why not just ignore it? It doesn't matter what the distance method is. If you wanted some minor time saving, why not just set all the elements to 0?
>If you are traveling to
>Australia, let me know - our
>paths might cross.
No. I have to go to Bali first, then Beijing. It's all business, but I'll slot in some personal time in Bali (would be dumb not to!). I've been to Beijing so many times that's just another long business trip 😞
Richard
Feb 25, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Feb 25, 2009
03:00 AM
>But why not just ignore it? It doesn't
>matter what the distance method is. If
>you wanted some minor time saving, why
>not just set all the elements to 0?
Ahhh - because I was trying different options and didn't come back and finish it off. It started off being set to zero, then I realised Ward needed the data supplied. So I set the Null to contain the data - but that wasn't very logical, so I made sure I passed the data to both methods. Obviously I never came back and re-set Null to zeros.
>No. I have to go to Bali first, then
>Beijing. It's all business, but I'll
>slot in some personal time in Bali
>(would be dumb not to!). I've been to
>Beijing so many times that's just
>another long business trip 😞
If you go to Bali then you will see lots of Australians. Have fun.
Philip
___________________
Nobody can hear you scream in Euclidean space.
>matter what the distance method is. If
>you wanted some minor time saving, why
>not just set all the elements to 0?
Ahhh - because I was trying different options and didn't come back and finish it off. It started off being set to zero, then I realised Ward needed the data supplied. So I set the Null to contain the data - but that wasn't very logical, so I made sure I passed the data to both methods. Obviously I never came back and re-set Null to zeros.
>No. I have to go to Bali first, then
>Beijing. It's all business, but I'll
>slot in some personal time in Bali
>(would be dumb not to!). I've been to
>Beijing so many times that's just
>another long business trip 😞
If you go to Bali then you will see lots of Australians. Have fun.
Philip
___________________
Nobody can hear you scream in Euclidean space.
Feb 26, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Feb 26, 2009
03:00 AM
Latest Additions/Revisions:
Cleaned up some of the variables and text.
Cleaned up Null distance to be zero (should have been this from the start).
Added more methods:
Single Linkage (Nearest Neighbour)
Clomplete Linkage (Furthest Neighbour)
Centroid Method (Average)
Updated Bar graph is set to match the length shown on the web site (which is different to my book):
http://www.wessa.net/rwasp_agglomerativehierarchicalclustering.wasp#output
However, the order of the bar graph is still out. The order is based on both distance and join path (New_Labels variable later in the worksheet) - but I don't have the time/care factor to do that right now.
Philip
___________________
Nobody can hear you scream in Euclidean space.
Cleaned up some of the variables and text.
Cleaned up Null distance to be zero (should have been this from the start).
Added more methods:
Single Linkage (Nearest Neighbour)
Clomplete Linkage (Furthest Neighbour)
Centroid Method (Average)
Updated Bar graph is set to match the length shown on the web site (which is different to my book):
http://www.wessa.net/rwasp_agglomerativehierarchicalclustering.wasp#output
However, the order of the bar graph is still out. The order is based on both distance and join path (New_Labels variable later in the worksheet) - but I don't have the time/care factor to do that right now.
Philip
___________________
Nobody can hear you scream in Euclidean space.
Feb 26, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Feb 26, 2009
03:00 AM
Philip, (+ Richard),
This is looking a very useful bit of work.
One very minor suggestion (actually applicable to all useful sheet), could you add a hyperlink at the top of the worksheet back to this (its)source thread. i.e. http://collab.mathsoft.com/read?120721,17
This is so that long after the file has been downloaded I and others can find all the background. I try to remember to update collab worksheets with such a link when I remember, but I have a good set of download that I can't find where the original thread is!
A great bit of work.
Philip Oakley
This is looking a very useful bit of work.
One very minor suggestion (actually applicable to all useful sheet), could you add a hyperlink at the top of the worksheet back to this (its)source thread. i.e. http://collab.mathsoft.com/read?120721,17
This is so that long after the file has been downloaded I and others can find all the background. I try to remember to update collab worksheets with such a link when I remember, but I have a good set of download that I can't find where the original thread is!
A great bit of work.
Philip Oakley
Feb 26, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Feb 26, 2009
03:00 AM
Sure thing.
From my perspective this has been collaborating at its best. Some things I would not have included, some things would have been wrong. I'm glad I've been able to contribute. Normally I sit back and just learn from the likes of Jean, Tom and yourself.
I'll include that link with the next round of mods.
Philip
___________________
Nobody can hear you scream in Euclidean space.
From my perspective this has been collaborating at its best. Some things I would not have included, some things would have been wrong. I'm glad I've been able to contribute. Normally I sit back and just learn from the likes of Jean, Tom and yourself.
I'll include that link with the next round of mods.
Philip
___________________
Nobody can hear you scream in Euclidean space.
Feb 26, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Feb 26, 2009
03:00 AM
On 2/26/2009 6:22:09 AM, pleitch wrote:
>Sure thing.
>
>From my perspective this has
>been collaborating at its
>best.
I agree. It's been very productive.
Richard
>Sure thing.
>
>From my perspective this has
>been collaborating at its
>best.
I agree. It's been very productive.
Richard
Feb 26, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Feb 26, 2009
03:00 AM
On 2/26/2009 8:39:23 AM, rijackson wrote:
>On 2/26/2009 6:22:09 AM, pleitch wrote:
>>Sure thing.
>>
>>From my perspective this has
>>been collaborating at its
>>best.
>
>I agree. It's been very productive.
>
>Richard
______________________
Hopefully Mona does catch that great piece
of work and have PTC include in a future DAEP.
Yes, Philip:
this forum is the "Mathcad Klondike",
a good pit to dig. BTW, as you are in
the medical fields, do you have in project
the Delaunay diagram ? I tried long time
ago but not to avail, because too novice.
Jean
>On 2/26/2009 6:22:09 AM, pleitch wrote:
>>Sure thing.
>>
>>From my perspective this has
>>been collaborating at its
>>best.
>
>I agree. It's been very productive.
>
>Richard
______________________
Hopefully Mona does catch that great piece
of work and have PTC include in a future DAEP.
Yes, Philip:
this forum is the "Mathcad Klondike",
a good pit to dig. BTW, as you are in
the medical fields, do you have in project
the Delaunay diagram ? I tried long time
ago but not to avail, because too novice.
Jean
Feb 27, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Feb 27, 2009
03:00 AM
>BTW, as you are in
>the medical fields, do you have in
>project
>the Delaunay diagram ? I tried long time
>ago but not to avail, because too
>novice.
No. I've never dealt with that.
Do you mean creating a triangle mesh, where... constraints...
If so - then no... but here is a link that might be helpful:
http://www.cs.cmu.edu/~quake/triangle.html
If not - what is it you are after?
Ta.
Philip
___________________
Nobody can hear you scream in Euclidean space.
>the medical fields, do you have in
>project
>the Delaunay diagram ? I tried long time
>ago but not to avail, because too
>novice.
No. I've never dealt with that.
Do you mean creating a triangle mesh, where... constraints...
If so - then no... but here is a link that might be helpful:
http://www.cs.cmu.edu/~quake/triangle.html
If not - what is it you are after?
Ta.
Philip
___________________
Nobody can hear you scream in Euclidean space.
Feb 27, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Feb 27, 2009
03:00 AM
On 2/27/2009 12:12:40 AM, pleitch wrote:
>>BTW, as you are in
>>the medical fields, do you have in
>>project
>>the Delaunay diagram ? I tried long time
>>ago but not to avail, because too
>>novice.
>
>No. I've never dealt with
>that.
>
>Do you mean creating a
>triangle mesh, where...
>constraints...
>
>If so - then no... but here is
>a link that might be helpful:
>http://www.cs.cmu.edu/~quake/t
>riangle.html
>
>If not - what is it you are
>after?
>
>Ta.
>Philip
>____________________________
Interesting applets in there.
http://www.diku.dk/hjemmesider/studerende/duff/Fortune/
It sounds a big project !
jmG
>>BTW, as you are in
>>the medical fields, do you have in
>>project
>>the Delaunay diagram ? I tried long time
>>ago but not to avail, because too
>>novice.
>
>No. I've never dealt with
>that.
>
>Do you mean creating a
>triangle mesh, where...
>constraints...
>
>If so - then no... but here is
>a link that might be helpful:
>http://www.cs.cmu.edu/~quake/t
>riangle.html
>
>If not - what is it you are
>after?
>
>Ta.
>Philip
>____________________________
Interesting applets in there.
http://www.diku.dk/hjemmesider/studerende/duff/Fortune/
It sounds a big project !
jmG
Mar 01, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Mar 01, 2009
03:00 AM
I see what you mean about biology.
The pattern looks exactly like cell structures (specifically squamous epithelial cells)

Philip
___________________
Nobody can hear you scream in Euclidean space.
The pattern looks exactly like cell structures (specifically squamous epithelial cells)
Philip
___________________
Nobody can hear you scream in Euclidean space.


{kind=link}
{kind=link}
{kind=link}